
Wallace���ͳ˷��������
����ʱ��:2008/6/24 0:00:00 ���ʴ���:2325
����
������������оƬ�У��˷����ǽ��������źŴ����ĺ��ģ�ͬʱҲ���������н������ݴ����Ĺؼ��������˷������һ�β��������ڻ����Ͼ���������������Ƶ���˷������ٶȺ�����Ż���������cpu��������˵�Ƿdz���Ҫ�ġ�Ϊ�˼ӿ�˷�����ִ���ٶȣ����ٳ˷�����������б�Ҫ�Գ˷������㷨���ṹ����·�ľ���ʵ����������о���
��4 booth�㷨��˷�����һ��ṹ
�����˷��������Ļ���ԭ�����������ɲ��ֻ����ٽ���Щ���ֻ���ӵõ��˻�����Ŀǰ�ij˷�������У�����booth�㷨�Dz��ֻ����ɹ������ձ���õ��㷨������nλ�з������˷�a��b��˵������ij˷���������n�����ֻ�������Գ���b���л���booth���룬ÿ���迼��3λ�����ڸ�λ����λ�����ڵ�λ�������������ֻ��ĸ������Լ��ٵ�[(n+1)/2]?? ��[x]ȡֵΪ������x����������ȷ��������0����1a����2a������2a��ʵ�֣�ֻ��Ҫ��a����һλ����ˣ����ڷ������˷����ԣ���4 booth�㷨�ȷ����ֿ�ݡ���������������˵��ֻ������λ��0��չ������������������ͬ����Ȼ��չ����ܵ��²��ֻ��ĸ������з������˷���1�����������㷨�ܺõر�֤��Ӳ���ϵ�һ���ԣ�������ʵ�֡�����32λ�˷���˵�����ָ�����ƣ�ͨ���������Ҫ��ӵIJ��ֻ�������18����
�����Բ��ֻ���ӣ����Բ��ò�ͬ�ļӷ������нṹ������ͬ�����нṹ��ֱ��Ӱ�����һ�γ˷�����Ҫ��ʱ�䣬��ˣ��ӷ������нṹ�Ǿ����˷������ܵ���Ҫ���ء��ظ����У�iterative array�����ia����wallace���ͽṹ����Ϊ���͵����ּӷ������нṹ��ia�ṹ���������ڰ�ͼʵ�֣����ٶ�����������������ϣ�wallace���ͽṹ�ǽ��г˷��������ļӷ������нṹ������ͳ��wallace���ͽṹ��·�������ӣ���ͼʵ�����ѡ�Ϊ�˽��������⣬�����Ƴ���һЩ���ӹ�ϵ��Ϊ�����ͽṹ������zm����os�������Ƕ��ǽ�ia����Ϊ���Σ�ÿ�γ�֮Ϊ�����������ڲ����Ӳ���ia�ṹ��������������������ӣ��Դ����������Ӹ��Ӷȣ��������ַ��������˲��ֻ���ӵ��ٶȡ�
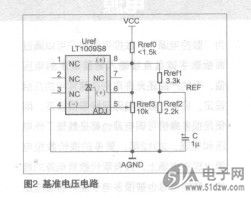
�ڶ����ͽṹ���иĽ���ͬʱ���������Ҳ�����˶Լӷ������л����ӷ���Ԫ�ĸĽ���wallace��������ķ����У�����csa����λ�����ӷ�������Ϊ������Ԫ�����ӷ����еġ�����������ǣ�ͨ��csa��������3��2��ѹ���ȶԲ��ֻ�������ѹ����ֱ�����ֻ�����������Ϊֹ����ͨ����λ���ݼӷ����Բ�����������α����ֲ���λ��ӵó������Ľ�����˺�dadda�����һ���µļӷ���Ԫ����Ϊ����j��k����������������j�������k�����������j�Q2k�������о���ʵ�������Ƿ���4-2ѹ������ʵ������5-3�����������нϺõ�ƽ���ԺͶԳ��ԣ�������Ϊ�����ӷ���Ԫ���ɵij˷��������������Ͼ���һ�������ƣ����4-2ѹ����Ҳ�ͳ�Ϊ��Ŀǰ�˷����н϶���õļӷ���Ԫ��
������ǰ��������a���е�ia���У��ṹ��Ϊ�������������ԣ�����ʱ���������������ṹ����b����wallace���ṹ�����ڲ���4-2ѹ������ΪΨһ�ļӷ���Ԫ����18���ܱ�4����������ڶ�18�����ֻ���������У���ȻҪ�����е��������ֻ����������wallace����ȡ�ķ����ǣ��Ƚ�16�����ֻ�ͨ������4-2ѹ������������������Ȼ����ʣ�µ��������ֻ�һ���ٽ���һ��4-2ѹ������c���е�һ��os���ṹҲ���������Ƶķ�����ֻ���ڴ������Ⱥ�˳���������ı䡣�����ֽṹ�����ƻ������ĶԳ��ԣ����·���IJ��ȳ�������˷���Ӳ����Դ���������˲��ֲ��ߵĸ��Ӷȡ���d���Dzο�����[5]�������һ�־����Ľ������ͽṹ����������ǣ���18�����ֻ���Ϊ3�飬�ȶ�ÿ���е�6�����ֻ���ͣ������������м������ٰ���6���м�����ӡ����ڶ�ÿ���е�6�����ֻ���ͣ����Բ�����ͬ�ṹ������4-2ѹ�����������ͺܺõؽ����˲��ֲ��ߵĸ��Ӷȡ���ȱ�����ڣ���4-2ѹ������6���м���������ӵĹ����У��Բ��ܱ���·����ƽ������⣬��ˣ�����ʹ�ؼ�·������ʱ�в���Ҫ�����ӡ�
csa��4-2ѹ�����ĵ�·�ṹ��ʱ�ӷ���
������Ȼcsa��4-2ѹ�����Ǽӷ���������Ҫ���õĻ�����Ԫ����ô�����б�Ҫ��csa��4-2ѹ�����ڵ�·���Է�����һ�·����Ƚϡ�csa�ĵ�·��ʵ���Ͼ���һλȫ��������ؼ�·������Ҫ�������������������ʱ������4-2ѹ����������������������csa����ͼ3��ʽ���������ɡ�
����������δ�����Ż��ĵ�·�ṹ�ܿ�����ɹؼ�·������Ҫ���ӳ����������ᵽ��4-2ѹ����ʵ��������5��Ȩ1�����룬����2��Ȩ2�������cout��c����1��Ȩ1�������s����������֮���Գ���Ϊ4-2ѹ��������5-3���������ǻ�������һ����ʵ�����˵�Ԫ���������к�����Ŀ����ʵ�ֵ�ѹ����Ϊ4:2��
�������⣬ͨ��ƽ��·�����ýṹʹ�����λ�����Թؼ�·�����ӳ����Ӱ�죬Ҳ����˵����c��s�ź������ʱ�䲻������cin�źţ���·�ؼ�·��Ϊ3������ŵ��ӳ١���90nm���������£�����mentor��˾��eldod���湤�ߵõ���ʵ�ʵ�·�ӳٷ����������1
����
������������оƬ�У��˷����ǽ��������źŴ����ĺ��ģ�ͬʱҲ���������н������ݴ����Ĺؼ��������˷������һ�β��������ڻ����Ͼ���������������Ƶ���˷������ٶȺ�����Ż���������cpu��������˵�Ƿdz���Ҫ�ġ�Ϊ�˼ӿ�˷�����ִ���ٶȣ����ٳ˷�����������б�Ҫ�Գ˷������㷨���ṹ����·�ľ���ʵ����������о���
��4 booth�㷨��˷�����һ��ṹ
�����˷��������Ļ���ԭ�����������ɲ��ֻ����ٽ���Щ���ֻ���ӵõ��˻�����Ŀǰ�ij˷�������У�����booth�㷨�Dz��ֻ����ɹ������ձ���õ��㷨������nλ�з������˷�a��b��˵������ij˷���������n�����ֻ�������Գ���b���л���booth���룬ÿ���迼��3λ�����ڸ�λ����λ�����ڵ�λ�������������ֻ��ĸ������Լ��ٵ�[(n+1)/2]?? ��[x]ȡֵΪ������x����������ȷ��������0����1a����2a������2a��ʵ�֣�ֻ��Ҫ��a����һλ����ˣ����ڷ������˷����ԣ���4 booth�㷨�ȷ����ֿ�ݡ���������������˵��ֻ������λ��0��չ������������������ͬ����Ȼ��չ����ܵ��²��ֻ��ĸ������з������˷���1�����������㷨�ܺõر�֤��Ӳ���ϵ�һ���ԣ�������ʵ�֡�����32λ�˷���˵�����ָ�����ƣ�ͨ���������Ҫ��ӵIJ��ֻ�������18����
�����Բ��ֻ���ӣ����Բ��ò�ͬ�ļӷ������нṹ������ͬ�����нṹ��ֱ��Ӱ�����һ�γ˷�����Ҫ��ʱ�䣬��ˣ��ӷ������нṹ�Ǿ����˷������ܵ���Ҫ���ء��ظ����У�iterative array�����ia����wallace���ͽṹ����Ϊ���͵����ּӷ������нṹ��ia�ṹ���������ڰ�ͼʵ�֣����ٶ�����������������ϣ�wallace���ͽṹ�ǽ��г˷��������ļӷ������нṹ������ͳ��wallace���ͽṹ��·�������ӣ���ͼʵ�����ѡ�Ϊ�˽��������⣬�����Ƴ���һЩ���ӹ�ϵ��Ϊ�����ͽṹ������zm����os�������Ƕ��ǽ�ia����Ϊ���Σ�ÿ�γ�֮Ϊ�����������ڲ����Ӳ���ia�ṹ��������������������ӣ��Դ����������Ӹ��Ӷȣ��������ַ��������˲��ֻ���ӵ��ٶȡ�
�ڶ����ͽṹ���иĽ���ͬʱ���������Ҳ�����˶Լӷ������л����ӷ���Ԫ�ĸĽ���wallace��������ķ����У�����csa����λ�����ӷ�������Ϊ������Ԫ�����ӷ����еġ�����������ǣ�ͨ��csa��������3��2��ѹ���ȶԲ��ֻ�������ѹ����ֱ�����ֻ�����������Ϊֹ����ͨ����λ���ݼӷ����Բ�����������α����ֲ���λ��ӵó������Ľ�����˺�dadda�����һ���µļӷ���Ԫ����Ϊ����j��k����������������j�������k�����������j�Q2k�������о���ʵ�������Ƿ���4-2ѹ������ʵ������5-3�����������нϺõ�ƽ���ԺͶԳ��ԣ�������Ϊ�����ӷ���Ԫ���ɵij˷��������������Ͼ���һ�������ƣ����4-2ѹ����Ҳ�ͳ�Ϊ��Ŀǰ�˷����н϶���õļӷ���Ԫ��
������ǰ��������a���е�ia���У��ṹ��Ϊ�������������ԣ�����ʱ���������������ṹ����b����wallace���ṹ�����ڲ���4-2ѹ������ΪΨһ�ļӷ���Ԫ����18���ܱ�4����������ڶ�18�����ֻ���������У���ȻҪ�����е��������ֻ����������wallace����ȡ�ķ����ǣ��Ƚ�16�����ֻ�ͨ������4-2ѹ������������������Ȼ����ʣ�µ��������ֻ�һ���ٽ���һ��4-2ѹ������c���е�һ��os���ṹҲ���������Ƶķ�����ֻ���ڴ������Ⱥ�˳���������ı䡣�����ֽṹ�����ƻ������ĶԳ��ԣ����·���IJ��ȳ�������˷���Ӳ����Դ���������˲��ֲ��ߵĸ��Ӷȡ���d���Dzο�����[5]�������һ�־����Ľ������ͽṹ����������ǣ���18�����ֻ���Ϊ3�飬�ȶ�ÿ���е�6�����ֻ���ͣ������������м������ٰ���6���м�����ӡ����ڶ�ÿ���е�6�����ֻ���ͣ����Բ�����ͬ�ṹ������4-2ѹ�����������ͺܺõؽ����˲��ֲ��ߵĸ��Ӷȡ���ȱ�����ڣ���4-2ѹ������6���м���������ӵĹ����У��Բ��ܱ���·����ƽ������⣬��ˣ�����ʹ�ؼ�·������ʱ�в���Ҫ�����ӡ�
csa��4-2ѹ�����ĵ�·�ṹ��ʱ�ӷ���
������Ȼcsa��4-2ѹ�����Ǽӷ���������Ҫ���õĻ�����Ԫ����ô�����б�Ҫ��csa��4-2ѹ�����ڵ�·���Է�����һ�·����Ƚϡ�csa�ĵ�·��ʵ���Ͼ���һλȫ��������ؼ�·������Ҫ�������������������ʱ������4-2ѹ����������������������csa����ͼ3��ʽ���������ɡ�
����������δ�����Ż��ĵ�·�ṹ�ܿ�����ɹؼ�·������Ҫ���ӳ����������ᵽ��4-2ѹ����ʵ��������5��Ȩ1�����룬����2��Ȩ2�������cout��c����1��Ȩ1�������s����������֮���Գ���Ϊ4-2ѹ��������5-3���������ǻ�������һ����ʵ�����˵�Ԫ���������к�����Ŀ����ʵ�ֵ�ѹ����Ϊ4:2��
�������⣬ͨ��ƽ��·�����ýṹʹ�����λ�����Թؼ�·�����ӳ����Ӱ�죬Ҳ����˵����c��s�ź������ʱ�䲻������cin�źţ���·�ؼ�·��Ϊ3������ŵ��ӳ١���90nm���������£�����mentor��˾��eldod���湤�ߵõ���ʵ�ʵ�·�ӳٷ����������1
��һƪ��������˷Ŵ���
��һƪ����Ƶ��ˮ���ն˵����
 ��ؼ�������
��ؼ�������- 8-9MPS ������������/��������EVKT/PKT��
- 8-912V��6A ��·��ѹ��Դ���� IC
- 8-9���ֺ㶨��ͨʱ�����ģʽ��COT��
- 8-9ͬ����ѹPWM DC-DC���Ե�Դ������Ӧ�ü���
- 8-9 ADC ����������Ӧ������֮���ϵ̽��
- 8-9�����任�������ͷ����Ÿ��ŷ��������Ƽ���
- 8-8�������ѧ��ϻ���˲�������Hybrid�����ܽ���
- 8-8��������оƬʽ����˲�������SPD��Ӧ�����
- 8-8�ϡ������̹⼤����������շ��
- 8-8SPICEģ��ROHM Level 1��L1������Ӧ
- 8-8������̼���裨SiC��MOS����ģ��Ӧ��̽��
- 8-8��һ������ͨ�ŵĹ��շ���������оƬ
- ���IC�ͺ�
�������
- Wallace���ͳ˷��������
- �������Ƴ�������˫Ƶ��WiFiǰ��ģ��AFE
- CSR�Ƴ����ߴ�BlueCoreоƬ
- ��˼����ΪL�����״��Ƴ�50V LDMOS��
- ��Ƶ��ˮ���ն˵����
- �����������ڸ�Ч�ʷ��������ʷŴ�����RQA0
- Autosplice��Maxi-Clip����
- MIPS�Ƽ��ṩ�����������յĹ���֤�߱�
- TI��������ISO 15693���ij�ģѹR
- ���п����л��ٶȵ����źŷ�����
�Ƽ���������
- ����ѹ���ṩ
- ��ʼ��ʱ����ʹ��LM385��Ϊ����HIN202EC... [��ϸ]
- MPS ������������/��������EVKT/P
- 12V��6A ��·��ѹ��Դ���� IC
- ���ֺ㶨��ͨʱ�����ģʽ��COT��
- ͬ����ѹPWM DC-DC����
- ADC ����������Ӧ������֮
- �����任�������ͷ����Ÿ��ŷ�
- ��ý��Э������SM501��Ƕ��ʽϵͳ�е�Ӧ��
- ����IEEE802.11b��EPA�¶ȱ�����
- QUICCEngine�������ƶ�IP�������
- SoC���������IJ�ҵ����
- MPC8xxϵ�д�������Ƕ��ʽϵͳ��Դ���
- dsPIC�����ڽ�����Ƶ�����е�Ӧ���о�
 ��������44030402000607
��������44030402000607





