
- 1
- 2
- 3
- 4
- 5
- 6







 Ԫ����֪��Ʒ��
Ԫ����֪��Ʒ��





 ������������Ϣ
������������Ϣ �û���¼
�û���¼ ic���ʹ�Ӧ��
ic���ʹ�Ӧ��







 �Ƽ�vip��ҵ
�Ƽ�vip��ҵ
- �������㴴�ڵ��ӿƼ�����˾
- ���о�ǵ����������ڣ�����˾
- ��������о���ӿƼ�����˾
- ������˳̩����������˾
- Խ����(����)ʵҵ����˾
- �������ϿƼ�����˾
- ��������˼����ӿƼ�����˾
- Դ��о�Ƽ������ڣ�����˾
- �����п����������˾
- �����������οƼ�����˾
- GERMANY XIANZHOU GROUP CO., LTD
- �����о���¡�Ƽ�����˾
- �¹����ܼ�������˾
- �����ʣ���ۣ�����˾
- �����в��ڼѵ��ӿƼ�����˾
- �����������ӿƼ�����˾
- �����к��컪�Ƽ�����˾
- �����л��۰뵼��(����)����˾
- ����ΰ�����Ƽ�����˾
- ���������ػԵ�������˾
- �������ܿƼ�����˾
- �����п����������˾
- �����д�Դʵҵ�Ƽ�����˾
- �Ͼ�������ӹɷ��й�˾
- о�ݣ����ڣ����ӿƼ�����˾
- �������ż�Դ��������˾
- ��������˳�˿Ƽ�����˾
- �����л�����Ƽ�����˾
- ����������Ƽ�����˾
- �峿�뵼�壨���ڣ�����˾
- ��������Ƽ�����˾
- ��������嫵��ӿƼ�����˾
- �������ܿƼ�����˾
- ������չ����ԣ�Ƽ�����˾
- �������Ƿ�ʢ��������˾
- ����������̩�Ƽ�����˾
- �����д��ε�������˾
- �������ÿƼ�����˾
- ��������ΰҵ�Ƽ�����˾
- HECC GROUP CO��LIMITED
- �����к����˵�������˾
- ������ʢ��ҵ��������˾
- �����и���о�Ƽ�����˾
- �����н������Ƽ�����˾
- �����������ӿƼ�����˾
- �������ÿƼ�����˾
- ��������˹�ֵ�������˾
- �������ڲ�о�Ƽ�����˾
- �����л�����Ƽ�����˾
- ����������о�Ƽ�����˾
 ������Ѷ
������Ѷ

- ȫ��Blackwell�ܹ�оƬƽ̨
- ���⣺ ȫ��Blackwell�ܹ�оƬƽ̨�� ��Ʒ���������칤�ա��ڴ���ơ�оƬ��ɡ��ص㡢ԭ����������̡���չ���Ƽ�������� ժҪ�� ȫ��Blackwell�ܹ�оƬƽ̨��һ��
- ����һ����������ʽ���ɵ������������
- �������оƬUPD78F0547GK(T)-8EU
- ����оƬNC7SZ66M5�������
- icоƬOXMPCI952-LQAG���ܽ���
- ���͵�EPROM�洢��оƬ
- ��PIC16C54C04/P������
- NXP i.MX 93ϵ�д���������
- GDDR7�ڴ������
- DELO������ʹ��ϵͳ
- ȫ�¶�ܵ��ʽλ�ô���������
- ������AFE90xϵ��оƬӦ�ýṹ
- ����MEMS������������Ӧ��
- ����UM-TM (6X10) IC оƬӦ����Ʒ�װ
- оƬUCT-EM (30X5) YE ����Ĵ���
- US-EMP (44X7) CUS �Ĵ����뷢չ




 ������������>
������������>
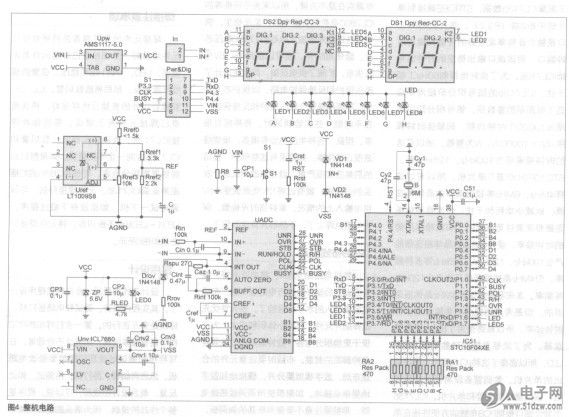
- ��Դ���Զ���Ⲣ���������Ӳ�������Ӧ��������ʵ�ֲ�������
- 7.5kW�ɱ�̵�Դʹ��TDK-Lambda�ĸ�����ϵͳ��ר�������У���ʹ��̨����ϵͳ�Ķ�̬��Ӧ�Լ��Ʋ����������ܿ��뵥̨��Դ��������
- ��ɼ̵��������ڲ��ߵ��źϽ����ι�����Ч�Կ��κδ������
- Wi-Fi(����LAN)��2.4GHzƵ����5GHzƵ������ӵ����������������
- ��Ʒ����EMI�����뿪����������ڸ�Ƶ��������ĵ������Ӧ��
- PCB�ϵ�ÿ������������Χ�Ľӵ������γ�һ����������
- ���м������ɵ��κ����͵�����ж����ÿ���ͨ�缼��ͨ��Э��
- �������ܹ�ƽ���ܿ���ʪ�Ⱥͺ��α仯Ӱ����ȵ��ʱ仯
- �㲥��������չ��֤�������������������ȶ��Ժͼ�����
- ���ߺͷ���оƬ�����I/Q���Լ����ʷŴ�������Ԥʧ�沨�ΰ������
- ����I/Q���Ⲩ�η������������û��ɱ��FPGA���
- ʹ��·����г���������Ƭ���ݺ���Ƭ���ͬʱ���ڵ�·��
- �������·��ѹ�������������鿪�����Ǵ���װһֻ������ֵ��ѹ�̵���
PDF�������� ����>
 ��ҵ����
��ҵ����
- ADS8688IDBTR ������������ԴADC2024-04-25
- ADS8588SIPMR ��������16λADC2024-04-25
- ADS8028IRTJR ��������8ͨ��ADC2024-04-25
- H7229FNL 120uH 100 Ohms��Ƶ��ѹ��2024-04-25
- HX5026NL��1000Base-T��Ƶ��ѹ���ֻ�2024-04-25
- TLV2254��������Ŵ��� 2024-04-25
- LMC6035ͨ������Ŵ���2024-04-25
- OPA4277��������Ŵ���2024-04-25
- THS6012��·������,��������Ŵ���2024-04-25
- TLV2772A2024-04-25
- TLE2161Mͨ������Ŵ���2024-04-25
- TLV2774Aͨ������Ŵ���2024-04-25
- THS4011M��������Ŵ���2024-04-25
- THS41402024-04-25
- OPA2704ͨ������Ŵ���2024-04-25
- OPA23562024-04-25
- LMV982-N2024-04-25
- OPA2363ͨ������Ŵ���2024-04-25
- LM239A-Q1�Ƚ���2024-04-25
- TLC2274A-Q1��������Ŵ���2024-04-25
- LM2901AV-Q1�Ƚ���2024-04-25
- TLC2264A-Q1��������Ŵ���2024-04-25
- TLV2374-EPͨ������Ŵ���2024-04-25
- THS7313��Ƶ�Ŵ���2024-04-25
- THS4520ȫ��ַŴ���2024-04-25
- LMP7300�Ƚ���2024-04-25
- LM293-EP�Ƚ���2024-04-25
- PGA113�ɱ�̺Ϳɱ�����Ŵ���2024-04-25
- TLV2262A-Q1��������Ŵ���2024-04-25
- INA129-EP�DZ��Ŵ���2024-04-25
- THS770012�ɱ�̺Ϳɱ�����Ŵ���2024-04-25
- LMH6551Q-Q1ȫ��ַŴ���2024-04-25
- LMV611ͨ������Ŵ���2024-04-25
- OPA4180��������Ŵ���2024-04-25
- TLC2274-HTͨ������Ŵ���2024-04-25
- G6RN-1A DC5�̵���2024-04-25
- 2615039336001����ģ��2024-04-25
- ACFL-3161-000E�������2024-04-25
- XZMYKXVG161W-A LED2024-04-25
- EKMC4611112K������2024-04-25
- S9S12XS256J0VAL2024-04-25
- KM-134-PUS��Яʽ����վ2024-04-25
- HSMW-C191 ChipLED2024-04-25
- R9A02G0214CNK#UA0 MCU2024-04-25
- VOA300-DEFG-X017T����˿2024-04-25
- KT1612A26000AAW19NAG�²�����2024-04-25
- MIRA050-1QM1WB FT SE ͼ����2024-04-25
- KT1612A26000AAW18TBL�������� 2024-04-25
- EPC902-CSP32-033������2024-04-25
- NX90ABB���۶�����2024-04-25
- PLN060-ER20A05Sƽ���ѹ��2024-04-25
- SN65HVD230DR2024-04-24
- 4525DO-DS5AI001DP2024-04-24
- 4525DO-SS3AS015AP2024-04-24
- 1 INCH-D-MV2024-04-24
- ADP51112024-04-24
- PS01-S400MP-3W2024-04-24
- LTC6090HS8E#TRPBF2024-04-24
- SSCDANN150PG2A32024-04-24
- SSCDANN015PAAA52024-04-24
- SSCDANN150PGAA52024-04-24
- SSCSNBN015PGAA52024-04-24
- SSCSNBN150PDAA52024-04-24
- SSCDRRN005PDAA52024-04-24
- SSCDANN030PAAA52024-04-24
- SSCDANN100PG5A52024-04-24
- SSCDANN015PD2A52024-04-24
- SSCDRRN001PDAA52024-04-24
- SSCDANN100PGAA52024-04-24
- SSCDRNN030PAAA52024-04-24
- SSCDRRN015PDAA52024-04-24
- 24PC15SMT2024-04-24
- SSCMRRN005PDAA32024-04-24
- SSCMNNN030PA2A32024-04-24
- SSCMRNN015PA3A32024-04-24
- SSCMRNN015PA3A32024-04-24
- SSCSNBN030PAAA52024-04-24
- OC5800L ���� 100V/5A MOS �������ѹ��ѹ��DC-DC2024-04-24
- OC5808L���� 100V/2A MOS �������ѹ��ѹ�� DC-DC 2024-04-24
- OC5330 �����ܵĿ��� ��ѹ�� LED ��������оƬ2024-04-24
- OC5338�����ܵĿ��� ��ѹ�� LED ��������оƬ2024-04-24
- OC5331�����ܵĿ��� ��ѹ�� LED ��������оƬ2024-04-24
- OC5338���ؽ�ѹ�� LED ����2024-04-24
- OC5816 ͬ��������ѹת����2A18V ͬ����ѹ DC-DC 2024-04-24
- OC7141���Խ�ѹ LED ��������IC2024-04-24
- OC4000����ѹ�� LED ������������оƬ2024-04-24
- OC4001����ѹ�� LED ������ ������оƬ2024-04-24
- SSCSNBN015PAAA52024-04-24
- SSCDRNT1.6BAAA32024-04-24
- IKW40N120H3 80A IGBT INFINEON/Ӣ����2024-04-24
- TIP122 NPN ���ֶپ���������ֻ�2024-04-24
- AD7606C-18BSTZ2024-04-24
- MAX33048EASA+2024-04-24
- AD7606C-18BSTZ2024-04-24
- TIP127��PNP���ֶپ����2024-04-24
- BTB16-800CWK2024-04-24
- BTB16-800SWK2024-04-24
- BTB16-600BWK2024-04-24
- BTB16-600CWK2024-04-24
- BTB16-600SWK2024-04-24
- BTA16-800BWA2024-04-24
- BTA16-800CWA2024-04-24
- BTA16-800SWA2024-04-24
- BTA16-600BWA2024-04-24
- BTA16-600CWA2024-04-24
- BTA16-600SWA2024-04-24
- BT138-800BWNB2024-04-24
- BT138-800BWAM2024-04-24
- BT138-800BWK2024-04-24
- BT138-800CWNB2024-04-24
- BT138-800CWAM2024-04-24
- BT138-800CWK2024-04-24
- BT138-800SWNB2024-04-24
- BT138-800SWAM2024-04-24
- BT138-800SWK2024-04-24
- BT138-600BWNB2024-04-24
- BT138-600BWAM2024-04-24
- BT138-600BWK2024-04-24
- MAX33048EASA+2024-04-24
- BT138-600CWNB2024-04-24
- BT138-600CWAM2024-04-24
- BT138-600CWK2024-04-24
- AD7606C-18BSTZ2024-04-24
- BT138-600SWNB2024-04-24
- BT138-600SWAM2024-04-24
- BT138-600SWK2024-04-24
- BTB12-800CWNB2024-04-24
- BTB12-800SWNB2024-04-24
- BTB12-600CWNB2024-04-24
- BTB12-600SWNB2024-04-24
- BTB12-800CWK2024-04-24
- BTB12-800SWK2024-04-24
- BTB12-800TWK2024-04-24
- BTA12-800CWA2024-04-24
- BTA12-800SWA2024-04-24
- BTA12-800TWA2024-04-24
- BTB12-600CWK2024-04-24
- BTB12-600SWK2024-04-24
- BTB12-600TWK2024-04-24
- BTA12-600CWA2024-04-24
- BTA12-600SWA2024-04-24
- BTA12-600TWA2024-04-24
- NCV75215DB001R2G2024-04-24
- BSM200GA170DN22024-04-24
- STB15810 �ⷨ�뵼��NMOS2024-04-24
- STB120NF10T4 �ⷨ�뵼��NMOS2024-04-24
- STB120N4F6 �ⷨ�뵼��NMOS2024-04-24
- STB100N6F7 �ⷨ�뵼��NMOS2024-04-24
- STB11NK50ZT4 �ⷨ�뵼��NMOS2024-04-24
- STB11NK40ZT4 �ⷨ�뵼��NMOS2024-04-24




�ͺ�Ŀ¼ ����>
- p5156
- p3048
- p1449
- p8589
- p7216
- p6242
- p2219
- p7385
- p6372
- p3343
- p8294
- p4458
- p5906
- p8026
- p4937
- p4575
- p8556
- p1868
- p5605
- p3981
- p172
- z-95
- g-44
- u-359
- i-241
- d-294
- m-1186
- d-478
- g-111
- k-32
- r-262
- f-4
- g-151
- c-88
- x-246
- t-97
- i-98
- v-89
- v-105
- h-305
- h-517
- s-643
- map-2565
- map-1888
- map-1768
- map-1446
- map-2467
- map-2375
- map-1506
- map-416
- map-1400
- map-2040
- map-2584
- map-2287
- A
- B
- C
- D
- E
- F
- G
- H
- I
- J
- K
- L
- M
- N
- O
- P
- Q
- R
- S
- T
- U
- V
- W
- X
- Y
- Z
- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9



















 �����ͺ�
�����ͺ�
- REC5-4809SRW/H2/C/SMD-R
- 20-101-0567
- 6012C SL002
- 8118PF303
- ASP2AK23PC
- B32361A2506J50
- EMC60DRTF
- P-18NF2X4
- OSTTR202551
- T4820209
- TIBPAL16R4-10CFN
- W2E142-BB05-87
- VJ1812A200KBRAT4X
- VE-JVX-EY-S
- VI-B6W-IY-S
- W3A4YC473MAT2A
- WLHAL4
- VI-JT1-CZ
- VE-B4M-MX
- SN75C3223DBR
- SR891A471JAR
- SN74LVC1G175DBVT
- MLG0603S0N4C
- MCR006YZPF2101
- P6SMBJ30CA
- MS27497E16B99PLC
- OSTOQ175351
- MS27468T25F24JA
- MS27466T25B46P
- MP8-3E-2E-0M
- MDM-21SH004F
- MCS04020D1802BE000
- ECQ-E2223KB
- D38999/20JD18HB
- ISO7221CDRG4
- GMM24DRES
- CMF553K9200FHBF
- DTS24W15-97SN
- ERJ-12SF22R6U
- EMC06DREH-S93
- DDTA122LE-7
- D38999/26JE8SN-LC
- D38999/24WJ29PN
- A22-20
- C1808C152J5GACTU
- C0805C394K4RACTU
- AOCJYA-13.000MHZ-E
- AML54-F10A
- 3386F-1-105
- AMC08DTES
- 8380-4SG-519
- 170-050-171L000
- 2966812
- 3640AC104MAT9A
- 06035C153J4T2A
- 0402SFF150F/24-2
- 06031U0R5BAT2A
- 0035.1251
- RG3216P-8201-D-T5
- XMLHVW-Q2-0000-0000LS3E8
 �Ƽ���ҵ
�Ƽ���ҵ
- �Ϻ��η���Ӽ�������˾
- �������ϿƼ�����˾
- ����������о��������˾
- ������о���Ƽ�����˾
- �����п�˼����ӿƼ�����˾
- ������������������˾
- �Ϻ�ɭ�۵��ӿƼ�����˾
- �Ͼ�������ӹɷ��й�˾
- ��۴�о���������˾
- �Ϻ�ͳӯ���ӿƼ�����˾
- �����к��ʢ���ӿƼ�����˾
- �������ܿƼ�����˾
- �������ÿƼ�����˾
- �����п����������˾
- ���ں�������Ƽ�����˾
- �������������ӿƼ�����˾
- �������հ뵼������˾
- ����������о�Ƽ�����˾
- �����п����������˾
- �������ڳϷ���������˾
- �������հ뵼������˾
- GERMANY XIANZHOU GROUP CO., LTD
- �峿�뵼�壨���ڣ�����˾
- ���������������Ƽ�����˾
- �����а���о�Ƽ�����˾
-
�������ӣ���ϵQQ��1445879221��
- ��ǿ������21ic�й��������й�ic��CCEE�羳����ѡƷ������Ϣ�����ҵ�����������������ӹ������ҵ�ά����̳�п�������ȫ������������繤ѧϰ������������ѷ�����Ϣ����ó���� �й�������оƬ��ѯ����������007����վ��ҵ��¼chinaAET �����豸ά�� ��Ȫ���й�����չ��������Ԫ������ѯ��������̳����ƹ��������ػ����Խ����������Ԫ�����ɹ� ��Դ��������Ϣ���й����������������DZ���114��Ϣ�������й����ֱ������²ɹ����й��洢�����Ӳ�Ʒ���� ����Դ�������ҵ���й������� �Ǽ�������
 ��������44030402000607
��������44030402000607











